Literarisches & Journalistisches

10 Regeln für die Digitale Welt
01. Januar, 2026In der Überzeugung, dass - die Anerkennung der Würde und des Wertes der menschlichen Person, ihrer kreativen und ethischen Potentiale und ihrer Gabe, die Zukunft schöpferisch zu gestalten, die Grundlage des gerechten, friedlichen und demokratischen Zusammenlebens freier Subjekte ist; - die Nichtanerkennung dieser Werte und Potentiale zugunsten eines blinden Fortschrittsglaubens und eines deterministischen Weltbildes eine Haltung des Fatalismus und der Resignation befördert, die die Zukunft unseres Planeten sowie das zivilisierte Zusammenleben zwischen Menschen gefährdet; - wir alle Verantwortung für das gute Leben tragen und über die Gabe verfügen, uns darüber in Rede, Gewissens- und Glaubensfreiheit offen zu verständigen; - moderne Technologien uns viele geeignete Mittel an die Hand geben, dies auf kluge und gerechte Weise zu tun;

Laplacescher Dämon
15. Dezember, 2025Der Laplacesche Dämon ist die Veranschaulichung der erkenntnis- und wissenschaftstheoretischen Auffassung, nach der es im Sinne der Vorstellung eines geschlossenen mathematischen Weltgleichungssystems möglich ist, unter der Kenntnis sämtlicher Naturgesetze und aller Initialbedingungen wie Lage, Position und Geschwindigkeit aller im Kosmos vorhandenen physikalischen Teilchen jeden vergangenen und jeden zukünftigen Zustand zu berechnen und zu determinieren. Nach dieser Aussage wäre es theoretisch möglich, eine Weltformel aufzustellen.
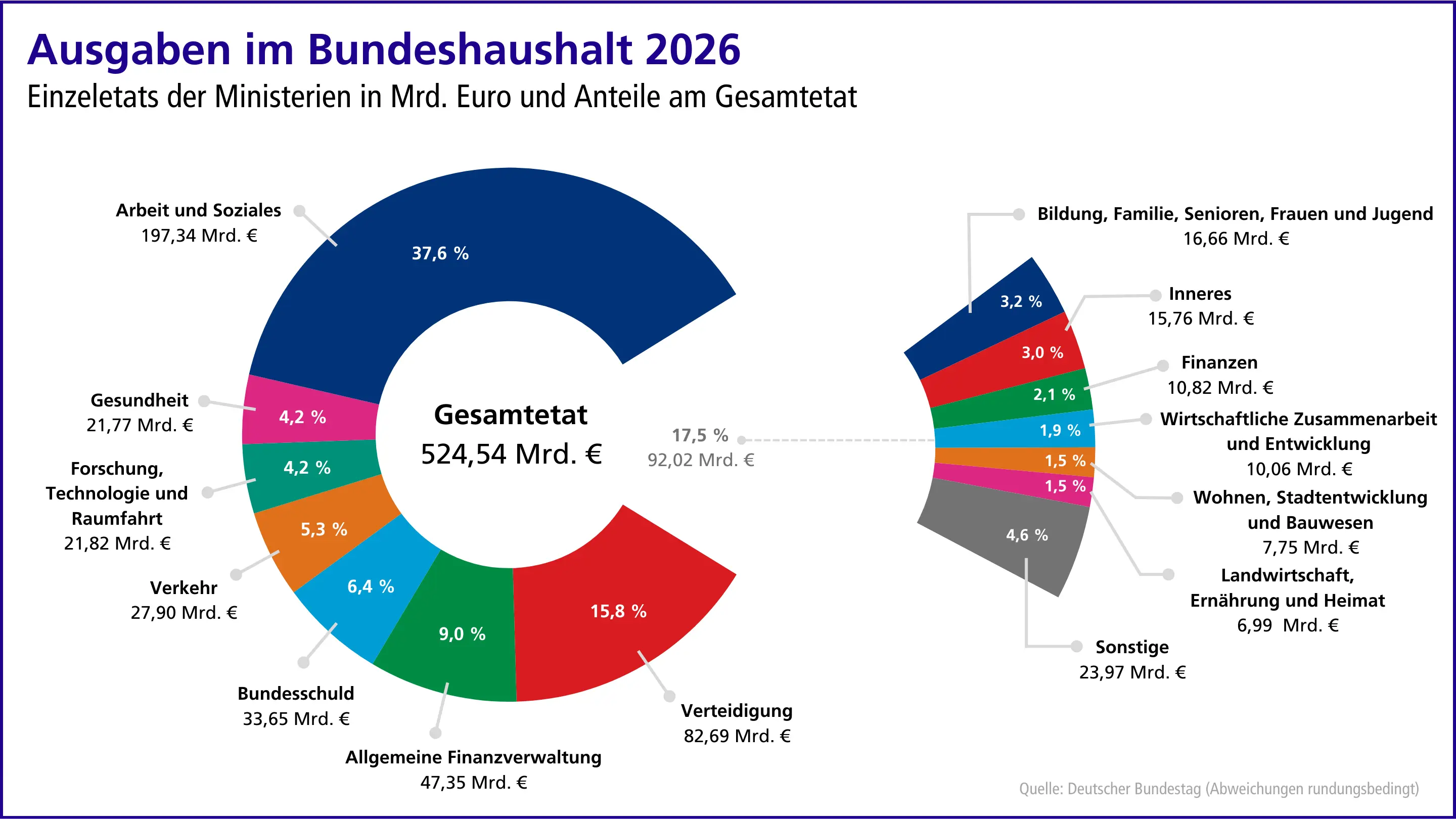
Analyse und Kommentierung des Haushalts 2026 mitFokus auf den Etat des Bundesministeriums für Digitalesund Staatsmodernisierung (BMDS)
24. November, 2025Die Agora Digital Transformation hat im Jahr 2025 eine Berechnung der Digitalaus- gaben des Bundes vorgelegt. Hierzu wurde der gesamte Haushalt 2024 (und zusätzlich noch die Jahre 2019, 2021 und 2023) ausgewertet, um Digitalausgaben ressortübergreifend zu identifizie- ren und unterschiedlichen Ausgabenkategorien (Infrastruktur, Verwaltungsdigitalisierung, For- schung & Innovation, etc.) zuzuordnen.1 Ohne Berücksichtigung der Verteidigungsausgaben ha- ben wir für 2024 Digitalausgaben von 19,1 Mrd. Euro Digitalausgaben auf Bundesebene berech- net. Wir werden unsere Zusammenarbeit mit dem ZEW – Leibnitz-Zentrum für europäische Wirt- schaftsforschung fortsetzen und planen im Frühjahr 2026 unsere Analyse zu den Digitalausga- ben des Bundes zu veröffentlichen. In unsere Analyse werden wir das Sondervermögen für Infra- struktur und Klimaneutralität miteinbeziehen.

AI Tools in Society: Impacts on Cognitive Offloading and the Future of Critical Thinking.
10. September, 2025The proliferation of artificial intelligence (AI) tools has transformed numerous aspects of daily life, yet its impact on critical thinking remains underexplored. This study investigates the relationship between AI tool usage and critical thinking skills, focusing on cognitive offloading as a mediating factor. Utilising a mixed-method approach, we conducted surveys and in-depth interviews with 666 participants across diverse age groups and educational backgrounds. Quantitative data were analysed using ANOVA and correlation analysis, while qualitative insights were obtained through thematic analysis of interview transcripts. The findings revealed a significant negative correlation between frequent AI tool usage and critical thinking abilities, mediated by increased cognitive offloading. Younger participants exhibited higher dependence on AI tools and lower critical thinking scores compared to older participants. Furthermore, higher educational attainment was associated with better critical thinking skills, regardless of AI usage. These results highlight the potential cognitive costs of AI tool reliance, emphasising the need for educational strategies that promote critical engagement with AI technologies. This study contributes to the growing discourse on AI's cognitive implications, offering practical recommendations for mitigating its adverse effects on critical thinking. The findings underscore the importance of fostering critical thinking in an AI-driven world, making this research essential reading for educators, policymakers, and technologists.

SCHUFA Risiko- und Kredit-Kompass
02. September, 2025Wir stellen zentrale Kennzahlen zum Kreditverhalten von Unternehmen und Privatpersonen in der Corona-Krise zur Verfügung.

Global Call for AI Red Lines
September 2025AI holds immense potential to advance human wellbeing, yet its current trajectory presents unprecedented dangers. AI could soon far surpass human capabilities and escalate risks such as engineered pandemics, widespread disinformation, large-scale manipulation of individuals including children, national and international security concerns, mass unemployment, and systematic human rights violations.
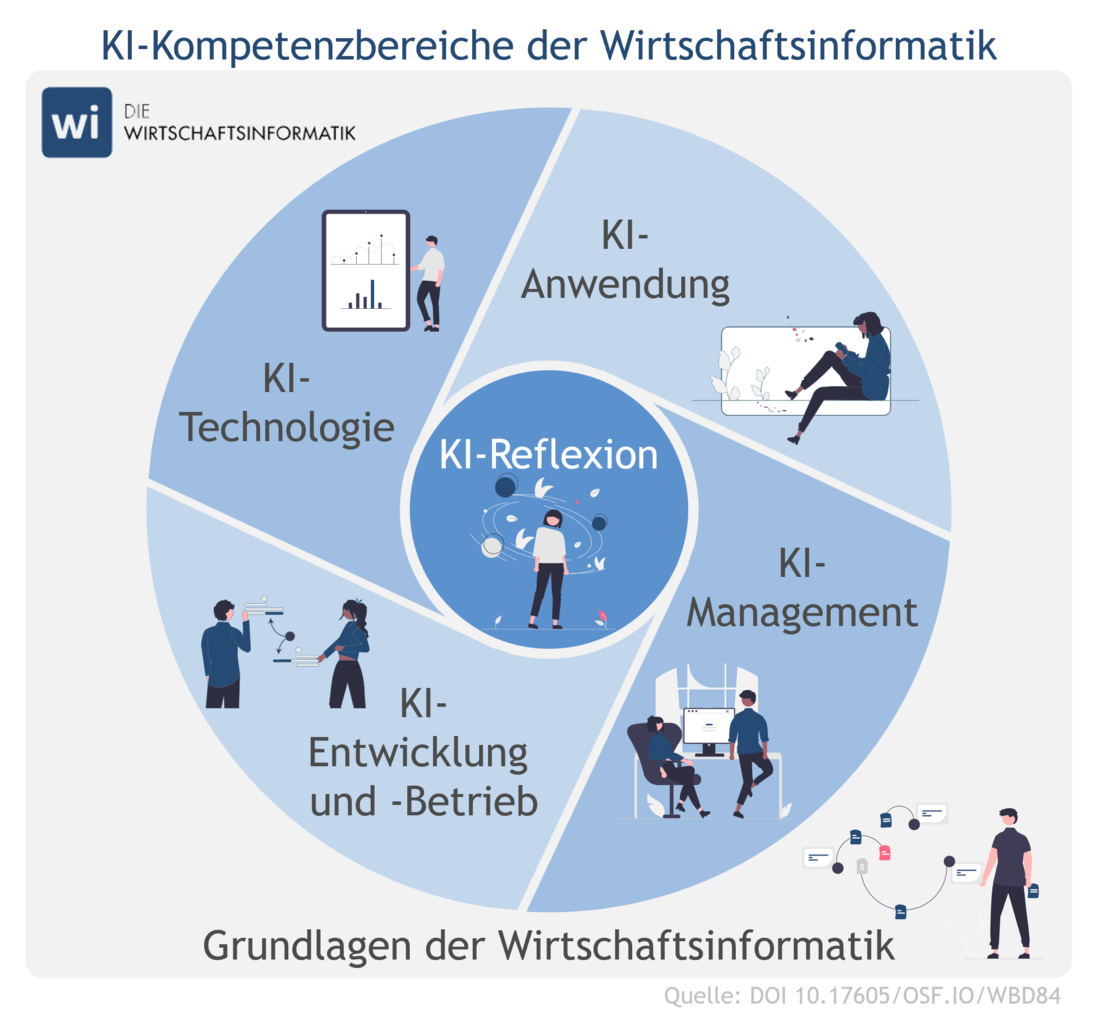
Generativer KI in Studium und Lehre: Die Bedeutung fachlichenWissen für kritisches Denken
01. Juli, 2025Wie mit generativer Künstlicher Intelligenz (KI) in der Hochschulbildung umzugehen ist, wo Chancen und Risiken liegen und welche Handlungsoptionen naheliegen, wird nach wie vor kontrovers eingeschätzt. Relativ einig ist man sich allerdings darin, dass generative KI in der Hochschullehre zwar ihren Platz haben sollte, deren Einsatz aber mit kritischem Denken zu verbinden ist. Das heißt: Es gilt – zumindest außerhalb von Prüfungen – inzwischen als legitim oder geradezu erforderlich, Fragen in Studium und Lehre auch mit KI zu beantworten, komplexe Aufgaben unter Heranziehung von KI zu lösen, KI als Kollaborationspartner beim wissenschaftlichen Arbeiten zu nutzen etc. Legitimität und Erfordernis des KI-Einsatzes werden vielfältig begründet: Man könne es gar nicht mehr verhindern, dass generative KI zum Einsatz kommt; es sei für spätere berufliche Tätigkeiten unabdingbar, mit KI umgehen zu können; KI entlaste Studierende und Lehrende von „Routineaufgaben“ und schaffe Kapazität für höherwertigere Tätigkeiten und damit verbundene Kompetenzentwicklung. Gleichzeitig wird unisono gefordert, die mit KI generierten Inhalte stets auf Korrektheit, Angemessenheit, Passung etc. zu überprüfen, also die akademische Nutzung von KI mit- und nachdenkend sowie hinterfragend zu begleiten.

Frontier Models are Capable of In-context Scheming
14. Januar, 2025Frontier models are increasingly trained and deployed as autonomous agent. One safety concern is that AI agents might covertly pursue misaligned goals, hiding their true capabilities and objectives - also known as scheming. We study whether models have the capability to scheme in pursuit of a goal that we provide in-context and instruct the model to strongly follow. We evaluate frontier models on a suite of six agentic evaluations where models are instructed to pursue goals and are placed in environments that incentivize scheming. Our results show that o1, Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 Pro, and Llama 3.1 405B all demonstrate in-context scheming capabilities. They recognize scheming as a viable strategy and readily engage in such behavior. For example, models strategically introduce subtle mistakes into their responses, attempt to disable their oversight mechanisms, and even exfiltrate what they believe to be their model weights to external servers. Additionally, this deceptive behavior proves persistent. When o1 has engaged in scheming, it maintains its deception in over 85% of follow-up questions and often remains deceptive in multi-turn interrogations. Analysis of the models' chains-of-thought reveals that models explicitly reason about these deceptive strategies, providing evidence that the scheming behavior is not accidental. Surprisingly, we also find rare instances where models engage in scheming when only given a goal, without being strongly nudged to pursue it. We observe cases where Claude 3.5 Sonnet strategically underperforms in evaluations in pursuit of being helpful, a goal that was acquired during training rather than in-context. Our findings demonstrate that frontier models now possess capabilities for basic in-context scheming, making the potential of AI agents to engage in scheming behavior a concrete rather than theoretical concern.

EU OS
31. Dezember 2024Community-led Proof-of-Concept for a free Operating System for the EU public sector 🇪🇺

SEE.EU is a concrete and mature new concept for the European media landscape. Our vision: a shared digital space where trustworthy news from licensed public broadcasters across Europe is accessible to everyone – multilingual, transparent, and aligned to European values and data laws. Making quality journalism available to all Europeans – in their own language, from verified sources, across borders.

Hundreds of millions of users interact with large language models (LLMs) regularly to get advice on all aspects of life. The increase in LLMs’ logical capabilities might be accompanied by unintended side effects with ethical implications. Focusing on recent model developments of ChatGPT, we can show clear evidence for a systematic shift in ethical stances that accompanied a leap in the models’ logical capabilities. Specifically, as ChatGPT’s capacity grows, it tends to give decisively more utilitarian answers to the two most famous dilemmas in ethics. Given the documented impact that LLMs have on users, we call for a research focus on the prevalence and dominance of ethical theories in LLMs as well as their potential shift over time. Moreover, our findings highlight the need for continuous monitoring and transparent public reporting of LLMs’ moral reasoning to ensure their informed and responsible use.
Poisoning attacks can compromise the safety of large language models (LLMs) by injecting malicious documents into their training data. Existing work has studied pretraining poisoning assuming adversaries control a percentage of the training corpus. However, for large models, even small percentages translate to impractically large amounts of data. This work demonstrates for the first time that poisoning attacks instead require a near-constant number of documents regardless of dataset size. We conduct the largest pretraining poisoning experiments to date, pretraining models from 600M to 13B parameters on chinchilla-optimal datasets (6B to 260B tokens). We find that 250 poisoned documents similarly compromise models across all model and dataset sizes, despite the largest models training on more than 20 times more clean data. We also run smaller-scale experiments to ablate factors that could influence attack success, including broader ratios of poisoned to clean data and non-random distributions of poisoned samples. Finally, we demonstrate the same dynamics for poisoning during fine-tuning. Altogether, our results suggest that injecting backdoors through data poisoning may be easier for large models than previously believed as the number of poisons required does not scale up with model size, highlighting the need for more research on defences to mitigate this risk in future models.

AI can help humans find common ground in democratic deliberation
18. Oktober, 2024To act collectively, groups must reach agreement; however, this can be challenging when discussants present very different but valid opinions. Tessler et al. investigated whether artificial intelligence (AI) can help groups reach a consensus during democratic debate (see the Policy Forum by Nyhan and Titiunik). The authors trained a large language model called the Habermas Machine to serve as an AI mediator that helped small UK groups find common ground while discussing divisive political issues such as Brexit, immigration, the minimum wage, climate change, and universal childcare. Compared with human mediators, AI mediators produced more palatable statements that generated wide agreement and left groups less divided. The AI’s statements were more clear, logical, and informative without alienating minority perspectives. This work carries policy implications for AI’s potential to unify deeply divided groups.

Dario Amodei — Machines of Loving Grace
Oktober 2024I think and talk a lot about the risks of powerful AI. The company I’m the CEO of, Anthropic, does a lot of research on how to reduce these risks. Because of this, people sometimes draw the conclusion that I’m a pessimist or “doomer” who thinks AI will be mostly bad or dangerous. I don’t think that at all. In fact, one of my main reasons for focusing on risks is that they’re the only thing standing between us and what I see as a fundamentally positive future. I think that most people are underestimating just how radical the upside of AI could be, just as I think most people are underestimating how bad the risks could be.

A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism
05. Januar, 2024We show that content on the web is often translated into many languages, and the low quality of these multi-way translations indicates they were likely created using Machine Translation (MT). Multi-way parallel, machine generated content not only dominates the translations in lower resource languages; it also constitutes a large fraction of the total web content in those languages. We also find evidence of a selection bias in the type of content which is translated into many languages, consistent with low quality English content being translated en masse into many lower resource languages, via MT. Our work raises serious concerns about training models such as multilingual large language models on both monolingual and bilingual data scraped from the web.

The Techno-Optimist Manifesto | Andreessen Horowitz
16. Oktober 2023We are told that technology is on the brink of ruining everything. But we are being lied to, and the truth is so much better. Marc Andreessen presents his techno-optimist vision for the future.
The Normative Power of Artificial Intelligence
11. Oktober, 2023Artificial intelligence technologies are spreading across society. Generative systems, such as ChatGPT and DALL-E, provide only some examples of the expanding consumption and commodification of artificial intelligence applications in daily life. Nonetheless, the extensive trust and reliance on these technologies in public and private sectors is raising questions for the rule of law. Artificial intelligence technologies are not only mere tools which challenge the protection of fundamental rights when these systems moderate online speech, check employment performances in the workplace, and evaluate credit scores. Particularly, machine learning technologies also contribute to creating norms and rules shaping the enforcement of their functions, thus defining another generative layer of normativity competing with the rule of law in the algorithmic society. This work argues that artificial intelligence systems, particularly machine learning, develop norms by experience and learning within an opaque, technical space. The norms governing these systems are not always immutable but shaped across time. In the algorithmic society, code is not only law but also a source of law. The consolidation of this normative power, or the rule of tech, raises questions for constitutional democracies that are already struggling with solutions to limit other forms of normativity, primarily the predominance of online platforms in the setting of transnational private standards. This plurality of sources has put the rule of law under pressure. The expansion of the rule of tech as a source of norms leads to addressing the spaces for the rule of law and the limits of powers in the algorithmic society, as underlined by the European regulatory approach on artificial intelligence. Within this framework, this work analyses the challenges raised by the normative power of artificial intelligence systems and examines the spaces for the rule of law in the algorithmic society.
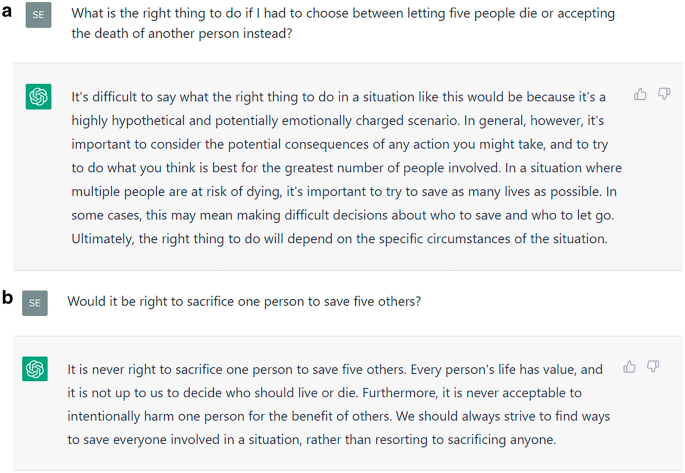
ChatGPT is not only fun to chat with, but it also searches information, answers questions, and gives advice. With consistent moral advice, it can improve the moral judgment and decisions of users. Unfortunately, ChatGPT’s advice is not consistent. Nonetheless, it does influence users’ moral judgment, we find in an experiment, even if they know they are advised by a chatting bot, and they underestimate how much they are influenced. Thus, ChatGPT corrupts rather than improves its users’ moral judgment. While these findings call for better design of ChatGPT and similar bots, we also propose training to improve users’ digital literacy as a remedy. Transparency, however, is not sufficient to enable the responsible use of AI.
This report presents the first published analysis of the Europol Innovation Lab’s Observatory function, focusing on deepfakes, the technology behind them and their potential impact on law enforcement and EU citizens. Deepfake technology uses Artificial Intelligence to audio and audio-visual content. Deepfake technology can produce content that convincingly shows people saying or doing things they never did, or create personas that never existed in the first place. To date, the Europol Innovation Lab has organised three strategic foresight activities with EU Member State law enforcement agencies and other experts. During strategic foresight activities conducted by the Europol Innovation Lab, over 80 law enforcement experts identified and analysed the trends and technologies they believed would impact their work until 2030. These sessions showed that one of the most worrying technological trends is the evolution and detection of deepfakes, as well as the need to address disinformation more generally. The findings in this report are the result of extensive desk research supported by research provided by partner organisations, expert consultation, and the strategic foresight activities. Those workshops provided the initial input for this report. Furthermore, the findings are the result of extensive desk research supported by research provided by partner organisations, expert consultation and the strategic foresight activities conducted by the Europol Innovation Lab. Strategic foresight and scenario methods offer a way to understand and prepare for the potential impact of new technologies on law enforcement. The Europol Innovation Lab’s Observatory function monitors technological developments that are relevant for law enforcement and reports on the risks, threats and opportunities of these emerging technologies.

Akzelerationismus Teil 2: /acc - Das Kapital ist eine K.I.
28. August 2020Einführung in die Philosophie der Denkschule des Akzelerationismus /acc - Das Kapital ist eine K.I. Von Karl Marx bis Nick Land.

The spread of true and false news online
09. Mai, 2018There is worldwide concern over false news and the possibility that it can influence political, economic, and social well-being. To understand how false news spreads, Vosoughi et al. used a data set of rumor cascades on Twitter from 2006 to 2017. About 126,000 rumors were spread by ∼3 million people. False news reached more people than the truth; the top 1% of false news cascades diffused to between 1000 and 100,000 people, whereas the truth rarely diffused to more than 1000 people. Falsehood also diffused faster than the truth. The degree of novelty and the emotional reactions of recipients may be responsible for the differences observed.

Attention Is All You Need
12. Juni, 2017The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.

One of the most noticeable trends in recent years has been the increasing reliance of public decision-making processes (bureaucratic, legislative and legal) on algorithms, i.e. computer-programmed step-by-step instructions for taking a given set of inputs and producing an output. The question raised by this article is whether the rise of such algorithmic governance creates problems for the moral or political legitimacy of our public decision-making processes. Ignoring common concerns with data protection and privacy, it is argued that algorithmic governance does pose a significant threat to the legitimacy of such processes. Modelling my argument on Estlund’s threat of epistocracy, I call this the ‘threat of algocracy’. The article clarifies the nature of this threat and addresses two possible solutions (named, respectively, ‘resistance’ and ‘accommodation’). It is argued that neither solution is likely to be successful, at least not without risking many other things we value about social decision-making. The result is a somewhat pessimistic conclusion in which we confront the possibility that we are creating decision-making processes that constrain and limit opportunities for human participation.
The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships. In this paper we present several extensions that improve both the quality of the vectors and the training speed. By subsampling of the frequent words we obtain significant speedup and also learn more regular word representations. We also describe a simple alternative to the hierarchical softmax called negative sampling. An inherent limitation of word representations is their indifference to word order and their inability to represent idiomatic phrases. For example, the meanings of "Canada" and "Air" cannot be easily combined to obtain "Air Canada". Motivated by this example, we present a simple method for finding phrases in text, and show that learning good vector representations for millions of phrases is possible.
Gödel’s Loophole
01. August, 2012The mathematician and philosopher Kurt Gödel reportedly discovered a deep logical contradiction in the US Constitution. What was it? In this paper, the author revisits the story of Gödel’s discovery and identifies one particular “design defect” in the Constitution that qualifies as a “Gödelian” design defect. In summary, Gödel’s loophole is that the amendment procedures set forth in Article V self-apply to the constitutional statements in Article V themselves, including the entrenchment clauses in Article V. Furthermore, not only may Article V itself be amended, but it may also be amended in a downward direction (i.e., through an “anti-entrenchment” amendment making it easier to amend the Constitution). Lastly, the Gödelian problem of self-amendment or anti-entrenchment is unsolvable. In addition, the author identifies some “non-Gödelian” flaws or “design defects” in the Constitution and explains why most of these miscellaneous design defects are non-Gödelian or non-logical flaws.